New I/O는 JDK1.4에서 새로 추가된 패키지이다. JDK1.4의 정식 명칭은 Java 2 Standard Edition JDK1.4이다. 흔히 Meriln이라고 부르는데 이는 개발시 프로젝트의 이름이다. 참고로 Meriln은 중세시대 아더왕의 전설에 나오는 마법사의 이름이기도 하지만 쇠황조롱이라는 매의 일종인 새의 이름이기도 하다.
New I/O는 java.nio 패키지로 제공되는 기능으로 크게 버퍼 관리 클래스류, 확장된 네트워크 그리고 파일 I/O, 문자 집합 지원, 그리고 정규식 문자 표현에 새로운 특징들과 개선된 성능을 제공한다. java.nio 패키지는 다음과 같은 클래스류로 나누어진다.
여기서 spi가 붙은 것을 볼 수 있는데 이는 SPI(Service Provider Interface)로 프로그래머가 제공하는 클래스로 대체할 수 있는 기능을 제공해준다. 이는 관련된 클래스들의 기본 구현을 프로그래머가 바꿀 수 있다는 뜻이 된다. 단, 이것은 특별한 경우에만 해당되므로 이런 것이 있다는 정도만 알아두자.
1> 특징.
- 기본 데이터형용 버퍼를 클래스로 제공해 준다.
- Character-set 인코더들과 디코더.
- 패턴과 어울린 기능은 Perl-style 정규식들로 설정.
- 채널, 새로운 I/O 추상화.
- 메모리 매핑과 파일의 lock(잡금장치)를 지원해주는 인터페이스.
- non-blocking 입출력이 가능.
2> 패키지 소개
- java.nio.package : 자바 기본형 유형에 맞는 버퍼 클래스들.
- java.nio.channels.package : 채널과 셀렉터.
- java.nio.charset.package : 문자 암호화들.
- java.nio.channels.spi.package : Service 프로바이더는 채널들을 위해 분류.
- java.nio.charset.spi.package : Service 프로바이더는 문자셑를 위해 분류.
- java.util.regex.package : 정규식들에 의해서 지정된 패턴들에 대해서 문자 표현에 대한 클래스들.
- java.lang.CharSequence.인터페이스 : 다양한 종류의 문자 순서에의 통일된 read 전용 액세스를 제공.
3> 정리
java.nio 패키지에서 눈여겨 봐둘것은 지금까지 지원이 되지 않았던 io의 nonblocking의 지원이다. 이러한 nonblocking의 지원으로 주요한 장점은 크게 다음 두가지이다.
- 스레드는 더이상 읽기나 쓰기에 블록킹되지 않는다.
- selector의 도입으로 클라이언트의 많은 접속을 처리할 서버의 부하가 상당히 줄어든다.
그리고 또 다른 한가지 java.nio 패키지에서 네트워크 기능이 강화 되었다. 채널의 도입으로 새롭게 강화된 네트워크를 다루려면 반드시 java.net 패키지의 이해는 필수이다.
==> 여기서는 nio패키지를 크게 두부분으로 나누어서 강좌를 할 예정이다. 하나는 java.nio의 Buffer류 클래스와 java.nio의 Channels 클래스이다.
2. nio의 Buffer
1> Buffer 계층도
nio패키지에는 각종 데이터를 담는 Buffer류 클래스들이 있다. 이들 클래스는 모두 Buffer클래스를 상속받는데 버퍼 클래스는 여러 종류가 있어서 각각 기본형 데이터에 맞는 클래스들이 존재한다. 이들은 다음과 같은 클래스 계층도를 가진다.
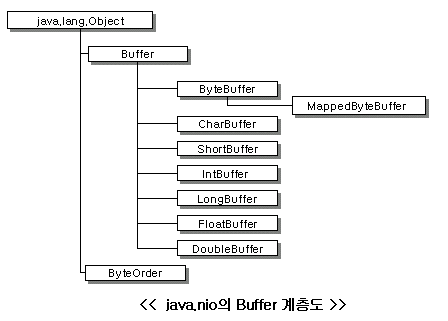
가장 기본이 되는 클래스는 Buffer 클래스이며 여기에서 기본적인 메서드들이 정의된다. 이를 상속받은 기본형 데이터를 위한 Buffer클래스들이 있다. 단, boolean형에 대한 버퍼는 없다. 전반적인 클래스를 정리해 보자.
2> 클래스의 개요
|
클래스명 |
정의 |
| Buffer |
가장 상위 클래스로서 기본 메서드를 가지고 있다. |
| ByteBuffer |
byte 버퍼 |
| ByteOrder |
저장되는 바이트 순서의 열거 형태에 따른 버퍼 |
| CharBuffer |
char 버퍼 |
| FloatBuffer |
float 버퍼 |
| IntBuffer |
int 버퍼 |
| LongBuffer |
long 버퍼 |
| MappedByteBuffer |
파일의 메모리 맵 영역을 내용으로 하는 direct byte 버퍼(데이터가 저장되는 메모리에 따른 버퍼) |
| ShortBuffer |
short 버퍼 |
| DoubleBuffer |
double 버퍼 |
표을 보면 낯설은 클래스가 두개 보인다. 바로 MappedByteBuffer 클래스와 ByteOrder 클래스이다.
먼저 MappedByteBuffer 클래스는 메모리 관리방식이 다른 클래스와 다른데, 버퍼는 만들기에 따라서 자바 가상머신내에 객체가 저장되는 메모리 공간인 Heap 버퍼가 있고 그외 다른 것들(변수들)이 저장되는 일반 버퍼가 있다. 여기서 Heap영역이 아닌 일반 메모리에 직접 접근하는 버퍼를 Direct Buffer라고 표현하는데 이 곳을 메모리 공간을 잡는 클래스이다.
ByteOder 클래스는 데이터가 어떤 순으로 구성될 것인지를 나타낸다. 컴퓨터는 두 바이트이상을 처리할때 처리효율이나 CPU 디자인 상의 문제로 데이터의 앞 바이트부터냐 뒤 바이트부터냐에 대한 해석의 순서에 차이가 있다. 이러한 차이는 데이터를 외부로 보내거나 받을때 영향을 미치기 때문에 데이터를 다루는 버퍼도 이를 고려해야 한다. 앞 바이트를 먼저 처리하는 CPU를 Big endian 이라고 표현하고 뒤 바이트를 먼저 처리하는 CPU는 앞 바이트에서 끝난다고 해서 Little endian 이라 한다. 만약 Little endian으로 동작하는 컴퓨터에서 만든 데이터 파일을 Big endian로 동작하는 컴퓨터에서 읽어 들여야 한다면 ByteOder 클래스로 데이터를 맞추어서 제대로 된 데이터를 얻을 수 있다. ByteOder 클래스의 클래스 메서드인 nativeOrder()메서드는 현재 동작하고 있는 컴퓨터의 CPU가 Big endian인지 Little endian인지 알려준다. 그럼 테스트를 해보자. 당장 메모장을 열고 다음과 같이 코딩을 해보자.........
/* ByteOrder 클래스의 nativeOrder() :
컴퓨터가 데이터를 어떤 순으로 처리하는지 검사
*/
import java.nio.*;
class BigLittleTest {
public static void main(String[] args) {
System.out.println("운영체제 종류 : "+System.getProperty("os.name")+"\n"+
"기본이 되는 네이티브의 바이트 순서 :"+ByteOrder.nativeOrder());
}
} |
3> 예외 클래스의 개요
버퍼 클래스에서도 예외가 있는데 주로 버퍼가 다 찼을때, 데이터를 집어넣으러고 하는 경우, 버퍼에서 읽어올 데이터가 없을경우 발생하는 예외다. 역시 이들 예외도 클래스로 미리 정의 되어 있다. 다음 표는 버퍼에 관련되 예외 클래스이다.
|
클래스명 |
정의 |
BufferOverflowException
|
데이터를 put()할때 버퍼의 limit에 이르렀을 때 슬로우 되는, 체크되지 않는 예외. |
| BufferUnderflowException |
데이터를 get()할때 버퍼의 limit에 이르렀을 때 슬로우 되는, 체크되지 않는 예외. |
| InvalidMarkException |
마크가 정의되어 있지 않은 상태로 버퍼를 리셋트 하려고 했을 때에 슬로우 되는, 미검사 예외. |
| ReadOnlyBufferException |
read 전용의 버퍼상에서 put 나 compact 라고 하는 컨텐츠 변경 메소드가 호출되면, 발생하는 예외. |
BufferOverflowException나 BufferUnderflowException 경우 버퍼 클래스류를 사용하면서 가장 많이 발생하게 될 예외가 될 것이다.....
자, 이제 버퍼 클래스를 자세히 살펴보자. 각 클래스의 메서드들은 파라미터 값만 각 데이터에 맞게 다르고 중복되는 메서드가 많으므로 주요 메서드를 위주로 살펴본다.
|
 자바가상머신은 Big endian이다.... 자바가상머신은 Big endian이다....
자바가상머신도 일종의 독립된 컴퓨터이기 때문에 이런 문제를 취급하는데 자바는 어떤 환경이든 실행되어야 한다는 기본 전제가 있다. 그래서 자바 클래스 파일은 실행되는 컴퓨터의 CPU에 관계없이 무조건 Big endian으로 동작하게끔 되어있다. 사실 이런 과정은 자바가상머신이 외부 CPU와 데이터 교환을 할때 자동적으로 처리되므로 사용자가 신경쓸 필요가 없다. |
3. 버퍼 기본 동작
Buffer 클래스류들을 살펴 보기전에 버퍼의 일반적인 동작에 대해 알아보자.
1> 버퍼의 기본 구조
버퍼는 시작과 끝이 잇는 일직서의 모양의 데이터 구조를 가진다. 버퍼는 객체 생성시 크기가 결정이 되며 한번 결정된 크기는 절대로 변하지 않는다. 따라서 크기를 늘이고자 한다면 다시 객체를 생성해 주어야 한다. 기본형 데이터들은 데이터 유형에 맞게 버퍼 객체를 생성해서 조작을 하며 이들 클래스들의 공통된 동작을 위해 java.nio.Buffer 클래스가 존재한다.
Buffer는 데이터를 관리하게 위해서 position,limit,capacity라는 중요한 값을 가지고 있다.
- position : 현재 읽거나 쓸 버퍼에서의 위치값이다. 인덱스 값이기 때문에 0부터 시작하며, 음수를 가지거나 limit보다 큰값을 가질 수 없다. 만약 position과 limit 의 값이 같아진다면 더이상 데이터를 쓰거나 읽을 수 없다는 뜻이 된다.
- limit : 버퍼에서 읽거나 쓸 수 있는 위치의 한계를 나타낸다. 이 값은 전체 버퍼에서 얼마큼의 메모리 공간을 사용할 것인지를 지정하는 것으로 capacity 보다 작거나 같은 값을 가지며 음수 값은 가지지 않는다. 인덱스 값이기 때문에 0부터 시작하며 최초 버퍼를 만들었을때는 capacity와 같은 값을 가진다.
- capacity : 버퍼가 사용할 수 있는 최대 데이터 개수(메모리 크기)를 나타낸다. 크기는 음수가 되지 않으며 한번 만들어지면 절대 변하지 않는다. 인덱스 값이 아니라 수량임을 주의하자,.
그외...
- mark : reset 메소드를 실행했을 때에 돌아오는 위치를 지정하는 인덱스로서 mark()로 지정할 ?있다. 주의할 것은 지정시 반드시 position 이하의 값으로 지정해 주어야 한다. position나 limit의 값이 mark 값보다 작은 경우,mark는 실행되지 않는다. mark()가 정의되어 있지 않은 상태로 reset 메소드를 호출하면 ,InvalidMarkException 가 발생한다.
각 값들의 관계는 다음과 같다.
0 <= mark <= position <= limit <= capacity
예를 들어 전체 크기가 10인 버퍼를 생성했다면 이를 다음과 같이 그림으로 나타내 본다면...,
각 숫자는 버퍼의 인덱스를 나타내고 처음 버퍼가 생성되면 그 초기값은 position이 0, limit는 capacity 값과 같으며 capacity 는 버퍼의 전체 크기를 가진다.
버퍼에서는 데이터를 효과적으로 다루기 위해서 capacity 안에서 position과 limit을 적절히 조절하게 된다.따라서 이들 세 값들을 잘 다룬다면 버퍼는 사용하기는 아주 편리할 것이다.
2> Buffer류 클래스의 get/put(읽기/쓰기) 메서드
버퍼의 동작에서 가장 중요한 동작은 바로 데이터를 읽고 쓰기일 것이다. 이때 사용하는 것이 put()과 get()이다. 이 메서드는 모든 버퍼류 클래스에서 사용하는데 크게 상대적 get/put과 절대적 get/put이 있다. 우선 상대적 get/put을 설명한다.
1) 상대적 get/put(읽기/쓰기)
상대적이라고 하는 이유는 position의 위치에 상대적인 동작을 하기 때문인데 position이 limit를 향해 읽거나 쓴만큼 증가한다. 따라서 상대적인 get/put 동작을 버퍼에 하면 현재 position에 있는 내용을 읽거나 positon 위치에 데이터를 쓴 다음 position값이 증가한다. 이 값은 limit과 같을 때까지 증가한다. 일단 position값이 limit값과 같아지면 그 다음부터는 get/put 동작을 할 수 없고 이들 값을 다시 재설정하는 메서드를 사용해야 한다. 만약 position값이 limit값까지 증가했는데도 get() 메서드를 사용한다면 BufferUnderflowException이 발생하며 put() 메서드를 사용한다면 BufferOverflowException이 발생한다.
2) 절대적 get/put(읽기/쓰기)
절대적이라 함은 get/put 동작시 현재의 position에 영향을 받지 않는 상태에서 limit 한도내에서 절대위치의 값을 읽거나 쓸 수 있다는 뜻이다. get/put 메서드 중에 인덱스 값을 인자로 받는 메서드가 있는데 이들 메서드를 사용해서 절대위치의 값을 읽거나 쓸 수 있다.
한꺼번에 여러 개의 데이터를 get/put 를 할 수 있는데 메서드 인자로 해당 데이터 배열을 넣어주면 된다. 예를 들어 CharBuffer클래스인 경우, get(char[] c)로, ByteBuffer클래스인 경우 put(byte[] b)로 사용한다. 이것은 position에 대해 상대적인 동작을 하며 역시 인자로 인덱스값을 주는 경우 절대위치에서 조작을 할 수 있다.
==> get/put 동작은 get()과 put()메서드로 수행되는데 이 메서드는 Buffer 클래스의 하위 클래스류에서 모두 가지고 있다. 동작은 같으나 인자나 리턴형은 다루는 데이터형-클래스-에 따라 다르다.
3> 테스트하기
이제 버퍼를 사용하는 간단한 예제를 다루어 보자. 우선 버퍼를 사용하려면 버퍼를 생성해야 한다. 당연하다. 버퍼를 생성하는 것은 간단하다. 각 XXXBuffer 클래스이 가지고 있는 클래스 메서드인 allocate() 메서드를 사용하면 간단하게 버퍼를 생성할 수 있다. 이때 인자로 버퍼의 초기 크기를 지정해준다. 형식은 다음과 같다.
IntBuffer buf=IntBuffer.allocate(10);
이는 int형 데이터를 다루는 크기가 10인 버퍼를 생성한다. 이제 예제를 보자.
import java.nio.*;
public class BufferTest1 {
public static void main(String[] args) {
//크기가 10인 IntBuffer버퍼 객체 생성
//이때 초기값은 pos는 0, limit는 capacity 값과 같다.
IntBuffer buf=IntBuffer.allocate(10);
System.out.println(buf);
buf.put(11);
System.out.println(buf.get(0));
System.out.println(buf);
buf.put(12);
System.out.println(buf.get(1));
System.out.println(buf);
buf.put(13);
System.out.println(buf.get(2));
System.out.println(buf);
buf.get(7);
buf.put(14);
buf.get(9);
System.out.println(buf);
}
}
|
<< 실행 결과 >>
|
C\>java BufferTest1
java.nio.HeapIntBuffer[pos=0 lim=10 cap=10]
11
java.nio.HeapIntBuffer[pos=1 lim=10 cap=10]
12
java.nio.HeapIntBuffer[pos=2 lim=10 cap=10]
13
java.nio.HeapIntBuffer[pos=3 lim=10 cap=10]
java.nio.HeapIntBuffer[pos=4 lim=10 cap=10] |
우선 버퍼 객체를 생성하고 이를 그대로 화면에 출력을 하면 position, limit, capacity가 차례대로 출력됨을 알 수 있는데 이는 toString()메서드 때문이다. 맨처음 출력은 버퍼의 초기값을 출력해 준다. pos는 0이고 lim과 cap는 값이 같다. 그리고 put()메서드를 이용해서 버퍼의 0번자리에 '11'이라는 값을 넣고 get()을 이용해서 출력한다. 그리고 나서 버퍼 객체를 출력하면 pos가 1칸 이동한 것을 알 수 있다. 그리고 총 5번의 put()메서드를 이용해서 값을 버퍼에 넣으니 pos가 put한 만큼 이동한 것을 알 수 있다. 결과를 보면 get을 하고 나면 pos는 이동하지 않는 다는 것을 알 수 있다. 이를 그림으로 나타내면... 다음과 같다.
|
(pos=4) |
(limit,capacity=10) |
|
Heap Buffer와 Direct Buffer
위의 예제 소스 결과에서 IntBuffer 객체를 출력하니 java.nio.HeapIntBuffer가 출력됨을 알 수 있다. 이는 버퍼 객체를 생성하면 메모리에 적절한 내부 구현 객체가 생기는데 allocate() 메서드로 생성하면 Heap Buffer를 얻을 수 있다. 이는 앞서 MappedByteBuffer 클래스 소개시 잠깐 언급을 했는데 Heap Buffer는 자바 가상머신내에 객체가 저장되는 메모리 공간인 Heap 버퍼를 말한다. 따라서 allocate() 메서드로 생성된 버퍼에서는 데이터가 Heap 버퍼에 저장이 된다. 하지만 이 공간이 아닌 일반 메모리 공간에 버퍼를 생성할 수 있는데 이를 Direct Buffer라 한다. 이 버퍼는 allocateDirect()메서드로 생성할 수 있다. Direct Buffer로 만들면 운영체제가 제공하는 메모리 입출력기능을 직접 쓰기때문에 입출력 속도가 매우 빠른 장점을 가지고 있다. 하지만 만들때에는 시간이 걸린다. 따라서 Direct Buffer는 대용량의 데이터를 다루고 오랜 기간동안 쓰면서 빠른속도가 필요한 곳에 적합하다. 단, Direct Buffer는 ByteBuffer 클래스만 사용가능하다. |
4. Buffer 클래스(java.nio.Buffer)
nio 패키지에서는 boolean형을 제외한 자바 기본 데이터형을 다룰 수 있는 Buffer류 클래스를 제공해 준다. Buffer 클래스는 버퍼로서의 기본적인 기능을 정의하며 이를 상속받는 기본형 데이터를 위한 Buffer 클래스들이 있다. 메모리 매핑 버퍼인 MappedByteBuffer 클래스와 CPU 타입에 따른 Big endian과 Little endian 구분을 위한 ByteOrder 클래스도 있다. 이들 클래스는 다루는 데이터형에 따라 XXXBuffer 라는 이름으로 클래스가 정의 되어있는데 그중에서 가장 상위 클래스는 Buffer 클래스이다. 따라서 버퍼 클래스류들은 이 Buffer 클래스가 가지고 있는 메서드는 다 사용할 수 있다.
이제 기본 메서드를 살펴보자.
1> Buffer 클래스의 메서드
ㅁ public final int capacity() : 이 버퍼의 용량(전체크기)를 리턴한다.
ㅁ public final int position() : 이 버퍼의 위치를 리턴.
ㅁ public final Buffer position(int newPosition) : 이 버퍼의 위치를 newPosition으로 설정한다.
ㅁ public final int limit() ; 이 버퍼의 limit를 리턴.
ㅁ public final Buffer limit(int newLimit) : 이 버퍼의 limit를 newlimit으로 설정한다.
ㅁ public final Buffer mark() : 이 버퍼의 현재 위치에 마크를 설정.
ㅁ public final Buffer reset()
: 버퍼의 위치를 이전에 마크 한 위치에 되돌린다. 그렇다고 마크의 값이 마크가 파기되거나, 변경되지 않는다.
==> 예외: InvalidMarkException - 마크가 설정되어 있지 않은 경우에 reset()메서드를 호출한 경우 발생
ㅁ public final Buffer clear()
: 이 버퍼의 위치(position)는 0으로 limit와 capacity값과 같게 설정한다. 마크값은 파기된다. 한 번 사용한 버퍼를 새롭게 다시 쓰기 위해 설정한다. 이 메소드는, read 조작 (put)을 실행하기 전에 주로 호출한다. 단, 버퍼내의 데이터를 지우는 것은 아니다. 단지 position과 limit를 초기값으로 설정한다.
ㅁ public final Buffer flip()
: 이 버퍼의 위치(position)는 0으로 limit와 position값과 같게 설정한다. 마크값은 파기된다. 이 메서드는 read 조작 (put)뒤, write()나 get()하기전에 이 메소드를 호출한다.
| ==> 예 |
buf.put(magic); // Prepend header
in.read(buf); // Read data into rest of buffer
buf.flip(); // Flip buffer
out.write(buf); // Write header + data to channel |
ㅁ public final Buffer rewind()
: 이 버퍼의 위치만 0 으로 설정되어 마크는 파기된다. 이는 이미 put한 것을 다시 get할때나 이미 put한 것을 취소할때 사용한다.
ㅁ public final int remaining()
: 현재 위치에서 limit까지 읽어들일 수 있는 데이터의 개수를 리턴한다.
ㅁ public final boolean hasRemaining()
: 현재 위치에서 limit까지 하나 이상의 차이가 나는지를 boolean형으로 리턴해 준다. 하나 이상의 차이가 나면 하나 이상의 데이터를 get()하거나 put()할 수 있기 때문에 BufferOverflowException 이나 BufferUnderflowException 을 피하기 위한 목적으로 사용된다. 이 버퍼내에 요소가 1 개 이상 존재하는 경우 true를 리턴.
ㅁ public abstract boolean isReadOnly()
: 현재 이 버퍼가 get()만 가능하며 put()은 금지되어있는지 알려준다.
2> 예제
import java.nio.*;
class BufferMethod {
public static void main(String[] args) {
//크기가 10인 IntBuffer 클래스 객체를 생성.
IntBuffer buf=IntBuffer.allocate(10);
System.out.println("생성된 후:"+buf);
for(int i=1;i<=5;i++){
buf.put(i);//1에서 5까지 버퍼에 저장
}
System.out.println("1에서 5까지 저장후 : "+buf);
buf.flip();//pos:0, limit=pos
System.out.println("flip():"+buf);
System.out.println("remaining():"+buf.remaining());//읽어들일수 있는 데이터수
buf.clear();//pos:0 , limit=cap
System.out.println("clear():"+buf);
System.out.println("remaining():"+buf.remaining());
for(int i=0;i<10;i++){
System.out.print(buf.get(i)+",");//출력
}
buf.position(5);//현재 버퍼의 위치를 5로 지정
System.out.println("\n"+"버퍼의 pos를 5로 설정한 후 :"+buf);
for(int i=101;i<=105;i++){
buf.put(i);//1에서 5까지 다시 다른 값을 버퍼에 저장
}
buf.rewind();//pos 값만 0으로
while(buf.hasRemaining()){
System.out.print(buf.get()+",");//출력
}
System.out.println("\n"+"isReadOnly() : "+buf.isReadOnly());
}
}
|
<< 실행 결과 >>
|
C\>java BufferMethod
생성된 후 : java.nio.HeapIntBuffer[pos=0 lim=10 cap=10]
1에서 5까지 저장후 : java.nio.HeapIntBuffer[pos=5 lim=10 cap=10]
flip() : java.nio.HeapIntBuffer[pos=0 lim=5 cap=10]
remaining() : 5
clear() : java.nio.HeapIntBuffer[pos=0 lim=10 cap=10]
remaining():10
1,2,3,4,5,0,0,0,0,0,
버퍼의 pos를 5로 설정한 후 : java.nio.HeapIntBuffer[pos=5 lim=10 cap=10]
1,2,3,4,5,101,102,103,104,105,
isReadOnly() : false |
이 예제는 편의를 위해 IntBuffer를 사용했다. 소스를 보면 먼저 크기 10의 버퍼를 만들고 화면에 출력을 했는데 position이 0이고 limit와 capacity가 10임을 확인할 수 있다.(pos=0 lim=10 cap=10) 이것이 버퍼의 초기값이다. 그러고 나서 put()을 한 이후에 position이 put()한만큼 이동한 것을 알 수있다.(pos=5 lim=10 cap=10) 그리고 flip() 메서드를 호출하고 확인하면 position가 0으로 가고 limit가 position위치로 오는 것을 확인한다.(pos=0 lim=5 cap=10) remaining()메서드로 position에서 limit까지 5개의 데이터가 있음을 알수 있다. clear()를 호출해서 다시 limit를 capacity와 같은 값으로 설정하고(pos=0 lim=10 cap=10) remaining()메서드를 호출하면 이번에는 position에서 limit까지 10개의 데이터가 있음을 알수 있다. get을 해서 화면에 데이터를 출력하면 값이 10개 출력됨을 알 수 있다.(1,2,3,4,5,0,0,0,0,0) position(5)으로 설정을 하고(pos=5 lim=10 cap=10) 101에서 105까지 값을 put한다. position를 5로 설정한 이유는 기존의 값을 유지하고 다음 데이터를 이어쓰기위해서이다. 다시 101에서 105까지 put하고 나면 position는 10이되는데 이를 get하기 위해 rewind()메서드를 호출해서 다시 position을 0으로 설정한다.(pos=0 lim=10 cap=10) 이렇게 채워진 값들을 while 반복문에서 hasRemaining()를 조건으로 검사해서 get한다. 좀 복잡한거 같지만 천천히 그림을 그려 보면 훨씬 이해가 쉽다. 다음 그림을 보고 정리하자...
1. 버퍼 생성 --> 아직 데이터가 put되지 않았다. 그럼 기본 초기값이 들어간다.
| (pos=0) |
(limit=capacity=10) |
2. 1에서 5까지 put한다.
|
(pos=5) |
(limit=capacity=10) |
3. flip() 메서드 호출
| (pos=0) |
(limit=5) |
(capacity=10) |
4. clear() 메서드 호출
| (pos=0) |
(limit=capacity=10) |
5. position(5) 메서드 호출
|
(pos=5) |
(limit=capacity=10) |
6. 101에서 105까지 값을 put()
|
1 |
2 |
3 |
4 |
5 |
101 |
102 |
103 |
104 |
105 |
7. rewind()메서드 호출
|
1 |
2 |
3 |
4 |
5 |
101 |
102 |
103 |
104 |
105 |
| (pos=0) |
(limit=capacity=10) |
8. 마지막으로 while 반복문에서 hasRemaining()를 조건으로 검사해서 get해서 데이터를 출력...끝......
|
메서드의 연쇄호출 가능이 가능하다.
위 메서드 대부분이 position의 이동을 설정하는 것이다. 그럼 내가 원하는 위치를 얻기위해서 여러 메서드르 호출해야 하는 경우가 많다. 이런 경우 하나하나 호출하는 것보다 연결해서 사용할 수도 있다. 예를 들어 다음과 같은 문장이 있다고 하자.
b.flip();
b.position(23);
b.limit(42);
이것들은, 보다 편한 방식으로 한다면...다음과 같이 연결해서 코딩한다.
b.flip(). position(23). limit(42);
|
5. Buffer의 하위 클래스
버퍼류 클래스에는 boolean형을 제외한 나머지 기본형 데이터형에 맞는 Buffer 클래스들이 있다. 이들 클래스들은 각각의 데이터형에 맞는 여러 기능의 메서드를 가지고 있다. 또한 이들 하위 클래스들의 특징은 모두들 abstract 클래스인데 그 이유는 Heap Buffer와 Direct Buffer의 구분때문이다. 이들을 객체화 할때 allocate()메서드를 이용하는데 이때는 Heap Buffer를 사용한다. Direct Buffer를 사용하기 위해서는 ByteBuffer 클래스의 allocateDirect()메서드를 이용하는데 이는 ByteBuffer만 가능하다. 하지만 다른 유형의 버퍼로 변환하는 것은 가능하다. 따라서 버퍼류 클래스 객체 생성을 하는 allocate()메서드는 각각 클래스에 맞게 정의되어 있어서 그형의 클래스 객체를 리턴한다.
각 버퍼류 클래스마다 공통된 메서드가 거의 주류를 이루므로 한꺼번에 설명하겠다. 기능은 같으나 각 인자형이나 리턴형은 각 클래스에 따라 다르다라는 것을 알고 하나씩 살펴보자.
1> Buffer의 하위 클래스들의 주요 메서드
ㅁ allocate(int capacity)
: 각각의 버퍼 클래스형 객체 리턴(Heap Buffer)
ㅁ wrap(기본형 데이터 배열)
ㅁ wrap (기본형 데이터 배열, int offset, int length)
: 해당 기본형 데이터 유형 배열을 인자로 주면 이 배열이 해당 버퍼에 put되어서 클래스형 객체 리턴(Heap Buffer), 즉 버퍼생성과 동시에 데이터 저장이다.
ㅁ array()
: 현재 버퍼가 데이터를 저장하는데 쓰고 있는 기본형 데이터형의 배열을 리턴한다. 단 이 메서드는 hasArray() 메소드가 true를 리턴하는 경우에만 사용한다.hasArray() 메소드가 true를 리턴하려면 Direct Buffer가 아니며 데이터 관리를 배열로 하고 있는 경우여야 한다.
ㅁ abstract boolean isDirect ()
: 현재 버퍼가 Direct Buffer인지 아닌지를 리턴. Direct Buffer이면 true를 리턴한다.
ㅁ asReadOnlyBuffer()
: read 만 가능한 버퍼를 리턴.
ㅁcompact()
: 현재 position과 limit 사이에 남아있는 데이터들을 모두 버퍼 맨 앞쪽으로 이동시킨다. 그리고 position은 이들 데이터의 맨 마지막 칸으로 동하고 limit는 capacity와 같은 값을 가진다. 이메서드는 다른 메서드와는 달리 위치값뿐만아니라 데이터들의 이동이 있다는 점이 다르다.
예를 들어 다음 그림과 같이 현재 position이 4이고 limit가 7이라고 하자.
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
(pos=4) |
|
(limit=7) |
|
|
(cap=10) |
이 상태에서 compact()메서드를 호출하면 position과 limit 사이의 데이터들을 맨 앞으로 이동시키고 위치는 그 다음 칸으로 이동하고 limit는 capacity와 같은 값을 가진다.
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
(pos=3) |
|
|
|
|
(limit=cap=10) |
ㅁ slice()
: 현재 position과 limit 의 범위를 별도의 버퍼로 만들어서 리턴해 준다. 즉 잘라내기라 생각하면 된다. 이것은 데이터는 공유하지만 position과 limit , mark값을 별도로 갖는 것으로 어느 한쪽에서 데이터를 수정하면 다른 한쪽도 수정한 데이터를 볼 수 있다. 이렇게 만들어진 새로운 버퍼는 position는 0으로, limit는 capacity와 같은 값을 가진다. mark는 재설정해 주어야 한다. 또 버퍼가 Heap Buffer라면 새로 생긴 버퍼도 Heap Buffer이며, 읽기전용이면 새 버퍼도 읽기전용이다.
예를 들어 다음 그림과 같은 버퍼를 slice()를 호출해서 새로 버퍼를 만든다면.. 그림과 같다.
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
(pos=4) |
|
(limit=7) |
|
|
(cap=10) |
|
0 |
1 |
2 |
|
<--새로 생긴 버퍼 |
|
(pos=0) |
|
|
(limit=cap=10) |
ㅁ duplicate()
: 데이터를 공유하는 또 하나의 버퍼를 생성해 주는데 이는 데이터 값만 복사되는 slice()와는 달리 position과 limit , mark 같은 모든 값이 그대로 복사된다. 즉 통째로 복사가 된다. 다만 복사된 이후에 position과 limit , mark값을 별도로 가진다. 그래서 내용만 공유하고 position과 limit , mark값는 따로 조작이 가능하다.
예를 들어 다음 그림과 같은 버퍼를 duplicate()를 호출해서 새로 버퍼를 만든다면.. 그림과 같다.
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
(pos=4) |
|
(limit=7) |
|
|
(cap=10) |
데이터를 공유하는 또 다른 버퍼 생성
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
(pos=4) |
|
(limit=7) |
|
|
(cap=10) |
2> 예제
import java.nio.*;
class SubBuffer {
public static void main(String[] args) {
System.out.println("-----------wrap()로 배열을 통째로 버퍼에 넣기 ");
int i[]={10,20,30,40,50,60,70,80,90,100};
// wrap()로 버퍼 생성과 동시에 데이터 put
IntBuffer buf=IntBuffer.wrap(i);
// 제대로 들어갔는지 데이터를 get해서 확인
while(buf.hasRemaining()){
System.out.print(buf.get()+",");
}
// position/limit/capacity확인
System.out.println("\n넣은후 : "+buf);
System.out.println("\n-----------array()로 반대로 버퍼를 배열로------");
// 버퍼의 데이터를 배열로 리턴, 이때 hasArray()가 true를 리턴해야 된다.
if(buf.hasArray()){
int a[]=buf.array();
// 배열 출력
for(int x=0;x<a.length;x++)
System.out.print(a[x]+",");
}
System.out.println("\n넣은후 : "+buf);
System.out.println("\n-----------compact()로 3부터 10까지 테이터를 맨앞으로------ ");
buf.position(3);
buf.compact();
System.out.println(buf);
for(int s=0;s<10;s++){
System.out.print(buf.get(s)+",");//출력
}
System.out.println("\n\n-----------duplicate()로 복사하기------- ");
IntBuffer buf2=buf.duplicate();
System.out.println("복사\n"+buf2);
buf.position(3);
System.out.println("원본 pos를 3으로 변경 :\n"+buf);
System.out.println("복사본은 ?:\n"+buf);
System.out.println("복사본 내용--");
for(int s=0;s<10;s++){
System.out.print(buf2.get(s)+",");//출력
}
System.out.println("\n\n-----------slice()로 자르기 ------");
IntBuffer buf3=buf.slice();
System.out.println("자르기\n"+buf3);
buf.position(3);
System.out.println("\n원본 pos를 3으로 변경 :\n"+buf);
System.out.println("자른 pos은 ?:\n"+buf3);
System.out.println("자른본 내용--");
while(buf3.hasRemaining()){
System.out.print(buf3.get()+",");//출력
}
System.out.println("\n\n-----------원본 데이터를 바꾼다. ------");
buf.clear();
for(int s=0;s<5;s++){
buf.put(s);//0에서 4까지 버퍼에 저장
}
System.out.println("\n바뀐 원본 : ");
for(int s=0;s<10;s++){
System.out.print(buf.get(s)+",");//출력
}
buf2.clear();
System.out.println("\n복사본은? : ");
for(int s=0;s<10;s++){
System.out.print(buf2.get(s)+",");//출력
}
buf3.clear();
System.out.println("\n자른본은? : ");
while(buf3.hasRemaining()){
System.out.print(buf3.get()+",");//출력
}
}
}
|
<< 실행 결과 >>
|
C\>java SubBuffer
-----------wrap()로 배열을 통째로 버퍼에 넣기
10,20,30,40,50,60,70,80,90,100,
넣은후 : java.nio.HeapIntBuffer[pos=10 lim=10 cap=10]
-----------array()로 반대로 버퍼를 배열로------
10,20,30,40,50,60,70,80,90,100,
넣은후 : java.nio.HeapIntBuffer[pos=10 lim=10 cap=10]
-----------compact()로 3부터 10까지 테이터를 맨앞으로------
java.nio.HeapIntBuffer[pos=7 lim=10 cap=10]
40,50,60,70,80,90,100,80,90,100,
-----------duplicate()로 복사하기-------
복사
java.nio.HeapIntBuffer[pos=7 lim=10 cap=10]
원본 pos를 3으로 변경 :
java.nio.HeapIntBuffer[pos=3 lim=10 cap=10]
복사본은 ?:
java.nio.HeapIntBuffer[pos=3 lim=10 cap=10]
복사본 내용--
40,50,60,70,80,90,100,80,90,100,
-----------slice()로 자르기 ------
자르기
java.nio.HeapIntBuffer[pos=0 lim=7 cap=7]
원본 pos를 3으로 변경 :
java.nio.HeapIntBuffer[pos=3 lim=10 cap=10]
자른 pos은 ?:
java.nio.HeapIntBuffer[pos=0 lim=7 cap=7]
자른본 내용--
70,80,90,100,80,90,100,
-----------원본 데이터를 바꾼다. ------
바뀐 원본 :
0,1,2,3,4,90,100,80,90,100,
복사본은? :
0,1,2,3,4,90,100,80,90,100,
자른본은? :
3,4,90,100,80,90,100, |
소스가 좀 길다. 그 이유는 확인을 하기위한 출력문이 많아서 그런것 뿐 이런것들을 생략하면 반으로 줄어든다. 자 하나씩 그림과 함께 살펴보자.
1. 버퍼를 wrap() 로 생성과 동시에 배열을 데이터로 put()
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
(pos=0) |
|
|
|
|
|
|
|
(limit=cap=10) |
2. array()메서드로 버퍼에 저장된 데이터를 배열로 리턴 받는데 반드시 hasArray()가 true를 리턴해야 된다.
3. 우선 position(3)으로 버퍼의 현 위치를 3으로 설정한 다음 campact()메서드를 호출한다. 그러면 위치 3에서 limit가 10이므로 이 사이의 데이터 7개가 버퍼 맨 앞으로 이동하고 위치(pos)는 7로 이동, limit는 capacity와 같은 값을 가진다.
|
40 |
50 |
60 |
70 |
80 |
90 |
100 |
80 |
90 |
100 |
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
|
|
|
|
(pos=7) |
(limit=cap=10) |
4. duplicate() 메서드를 호출, 버퍼를 복사해서 새로운 버퍼를 buf2에 담는다. 이때 pos/limit/cap 값들이 그대로 복사됨을 알 수 있다.
|
40 |
50 |
60 |
70 |
80 |
90 |
100 |
80 |
90 |
100 |
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
<- buf(원본) |
|
|
|
|
|
|
|
|
(pos=7) |
(limit=cap=10) |
|
|
40 |
50 |
60 |
70 |
80 |
90 |
100 |
80 |
90 |
100 |
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
<- buf2(복사본) |
|
|
|
|
|
|
|
|
(pos=7) |
(limit=cap=10) |
|
5. 복사를 하고 나서 원본인 buf의 position을 3으로 바꾸어 보니 복사본인 buf2도 position가 3으로 바뀐것을 확인 할 수 있다.
6. 이번에도 버퍼를 하나 더 생성하는데 slice()를 이용해서 새로 생긴 버퍼를 buf3에 담든다.그럼 지금 원본인 buf의 pos가 3이고 limit가 10이므로 이 범위의 데이타로 buf3를 생성하므로 다음과 같은 그림이다.
|
40 |
50 |
60 |
70 |
80 |
90 |
100 |
80 |
90 |
100 |
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
<- buf(원본) |
|
|
|
|
(pos=3) |
|
|
|
|
(limit=cap=10) |
|
|
0
|
1 |
2 |
3 |
4 |
5 |
6 |
<- buf3(자른본) |
|
(pos=0) |
|
|
|
|
(limit=cap=7) |
|
7. 역시 여기서도 원본인 buf의 position을 3으로 바꾸었다. 하지만 복사본과는 달리 자르기를 한 buf3는 전혀 변화가 없음을 알 수 있다.
8. 이번에는 원본의 데이터를 바꾸면 복사본과 자른 버퍼의 데이터도 바뀌는 지를 알아본다. 우선 원본인 buf의 데이터의 위치 0번부터 5번까지 데이터를 0에서 4로 바꾸었다. 그리고 나서 복사본과 자른본의 데이터를 출력하니 역시 데이터가 바뀐것을 알 수있다. 이는 복사본과 자른본은 원본과 데이터를 공유한다는 것을 알 수있다. 하지만 복사본은 원본과 pos나 limit값들도 함께 공유하지만 자른본은 데이터만 공유함을 알 수 있다.
조금 복잡해 보이나 그림을 그려가면서 따져보면 이해할 수 있다. 자 그럼 버퍼류클래스들을 살펴볼텐데 대부분이 같은 기능을 가진다. 그중에서 추가 기능을 가진 ByteBuffer와 CharBuffer에 대해서 알아보자.
6. ByteBuffer 클래스
우선 api문서에 있는 ByteBuffer 클래스의 선언은 다음과 같다.
public abstract class ByteBuffer extends Buffer implements Comparable
|
선언부분을 보면 ByteBuffer 클래스는 Buffer 클래스를 상속하고 Comparable 인터페이스를 구현하고 있다. Buffer 클래스를 상속는 누누히 말해 온 것이고 Comparable 인터페이스를 구현한다는 것은 ByteBuffer 클래스가 compareTo()라는 메서드를 가지고 있기 때문이다. 이는 다른 Buffer 클래스의 하위 클래스도 다 마찬가지이다.
ByteBuffer 클래스의 특징은 다음과 같이 두가지로 들수 있다.
- Direct Buffer를 만들 수 있다.
- 다른 유형의 버퍼로 변환이 가능하다.
이는 사실 하나로 생각될 수 있는데 그것은 ByteBuffer 클래스가 Direct Buffer를 만들면 이 Direct Buffer를 다른 유형으로 변환해서 쓸 수 있기 때문이다.
1> ByteBuffer 클래스 추가 메서드
ㅁ public static ByteBuffer allocateDirect(int capacity)
: Direct Buffer를 생성한다. Direct Buffer는 자바가 제공하는 Heap 메모리를 쓰지 않고 운영체제가 제공하는 메모리를 사용하므로 만들때에는 시간이 걸린다. 하지만 입출력 속도가 매우 빠른 장점을 가지고 있다. 따라서 Direct Buffer는 대용량의 데이터를 다루고 오랜 기간동안 쓰면서 빠른속도가 필요한 곳에 적합하다. 또 다른 장점으로는 JNI를 통해 직접 접근이 가능하다. JNI는 native 코드이므로 Direct Buffer를 navtive 코드에 쓰거나 native 에서 수정한 코드를 자바에서 쓰는 것이 가능하다.
ㅁ 다른 유형으로 변환시키는 메서드 -> asXXXBuffer()
public abstract CharBuffer asCharBuffer()
public abstract DoubleBuffer asDoubleBuffer()
public abstract FloatBuffer asFloatBuffer()
public abstract IntBuffer asIntBuffer()
public abstract LongBuffer asLongBuffer()
public abstract ShortBuffer asShortBuffer()
이들 메서드로 변환된 ByteBuffer는 변환유형에 맞는 Buffer로서의 기능을 할 수 있게 된다.
ㅁ public final ByteOrder order()
: 해당 버퍼의 ByteOrder를 리턴
ㅁ public final ByteBuffer order(ByteOrder bo)
: 인자로 들어온 ByteOrder로 버퍼를 설정한다. 인자로는 바이트 순서인 BIG_ENDIAN 또는 LITTLE_ENDIAN 이 온다.
: 다른 클래스에서도 ByteOrder(바이트 순서)를 변경할 수 있는데, 이는 직접 변경할 수는 없고 ByteBuffer클래스에서 바꾼 다음 이른 변환해야 한다.
ㅁ getXXX()/putXXX()
: ByteBuffer는 여러 유형의 데이터를 put/get 할 수 있는 메서드가 있다. put/get 뒤에 해당 데이터형만 적으면 된다. 이는 ByteBuffer가 다른 유형의 버퍼로 전환될 수 있는 능력을 가지고 있기 때문이다. 예를 들어 다음과 같이 사용한다.
buf1.putChar('가');
buf1.putDouble(3.14);
buf1.putFloat(3.14f);
이를 다음과 같이 호출해도 상관없다.
buf1.putChar('가').putDouble(3.14).putFloat((float)3.14);
ㅁ public int compareTo(Object ob)
: 인자로 들어온 객체 ob와 비교해서 결과 값을 리턴해 준다. 이때 리턴값이 음수면 객체 ob보다 자신이 작다는 뜻이고, 0은 같다는 뜻, 양수는 객체 ob보다 자신이 크다는 뜻이다. 주의할 점은 반드시 유형이 같은 버퍼끼리 비교해야 한다.
2> 예제
import java.nio.*;
public class ByteBufferTest {
public static void main(String[] args) {
// 버퍼를 생성한다.
ByteBuffer buf1=ByteBuffer.allocate(25);
// ByteOder(데이터 순서)를 출력한다.
System.out.println("Byte order : "+buf1.order());
// 여러 유형의 데이터를 put한다.
buf1.putChar('가');
buf1.putDouble(3.14);
buf1.putFloat((float)3.14);
// buf1.putChar('가').putDouble(3.14).putFloat((float)3.14); 라고 해도 된다.
System.out.println("buf1 : "+buf1);
// 여러 유형의 데이터를 get한다.
System.out.println(buf1.getChar());
System.out.println(buf1.getDouble());
System.out.println(buf1.getFloat());
//새로운 버퍼 생성
ByteBuffer buf2=ByteBuffer.allocate(20);
// 데이터 int형을 put
for(int i=1;i<=5;i++){
buf2.putInt(i);
}
// 버퍼의 위치값을 0으로 설정
buf2.clear();
// ByteBuffer를 IntBuffer로 변환시킨다.
IntBuffer intbuf=buf2.asIntBuffer();
System.out.println("IntBuffer로 변환후 값은:"+intbuf);
while(intbuf.hasRemaining()){
System.out.println(intbuf.get());//출력
}
}
}
|
<< 실행 결과 >>
|
C\>java ByteBufferTest
Byte order : BIG_ENDIAN
buf1 : java.nio.HeapByteBuffer[pos=14 lim=25 cap=25]
가
3.14
3.14
IntBuffer로 변환후 값은:java.nio.ByteBufferAsIntBufferB[pos=0 lim=5 cap=5]
1
2
3
4
5 |
소스를 보면 ByteBuffer 를 생성하고 이것의 ByteOrder를 출력해보니 BIG_ENDIAN임을 확인할 수 있다. 이것은 운영체계와 별개의 값이다. 자바가상머신은 하나의 독립된 컴퓨터이기 때문이다. 그리고 char,double,float 형의 데이터를 putXXX()메서드로 넣고 있다. 그리고 나서 다시 get을 해서 출력한다.
다시 크기가 20인 바이트 버퍼를 생성하고 이번에는 int형의 데이터를 삽입했다. 그리고 나서 버퍼의 위치를 clear()메서드로 0으로 만들고 나서 ByteBuffer를 IntBuffer로 변환한다. 변환하기전에 반드시 버퍼의 위치를 0으로 만들주어야 한다. 그이유는 변환시 버퍼의 현재 위치부터 변환이 시작되기 때문이다. 변환된 객체 intbuf를 출력하면 position는 0이 되고 limit와 capacity가 5으로 바뀐것을 볼 수 있다. 이는 IntBuffer로 변환되면서 데이터 크기를 int형의 크기로 바꾸어 버리기 때문이다. 즉 총 크기가 20이니 int는 4바이트를 차지하니깐 이를 나누면 5이 나온다. 하지만 데이터는 int형이 아니라서 그 크기에 맞게 들어간 것이 보인다.
7. CharBuffer 클래스
CharBuffer는 char 데이터 유형을 대상하는 버퍼로 특징은 1.4부터 추가된 java.lang.CharSequence 인터페이스를 구현하고 있다는 점이다. 다음은 CharBuffer의 클래스 선언문이다.
public abstract class CharBuffer extends Buffer implements Comparable , CharSequence
|
CharSequence 인터페이스를 구현하기 때문에, 문자 순서를 받아들일 수 있는 장소이면 어디에서라도, char 버퍼를 사용할 수 있다. 예를 들어, 1.4부터 추가된 정규 표현의 패키지 java.util.regex 에서의 사용이 가능하다. 또한 wrap()메서드에서 char[] 배열 대신에 CharSequence 객체가 들어 올 수 있어서 String이나 StringBuffer를 wrap()해서 CharBuffer로 만들 수 있다.
|
CharSequence 인터페이스
JDK 1.4부터 추가된 인터페이스로서 CharSequence 는 읽어들일 수 있는 문자 순서를 나타낸다. 이 인터페이스는, 다양한 종류의 문자 순서에의 통일된 read 전용 액세스를 제공한다.
<< 메서드 >>
ㅁ char charAt (int index) : 지정된 인덱스 위치에 있는 문자를 리턴
ㅁ int length () : 이 문자 순서의 길이를 리턴.
ㅁ CharSequence subSequence (int start, int end) : 이 순서의 서브 순서인 신규 문자 순서를 리턴.
ㅁ String toString () : 이 순서와 같은 순서로 문자를 포함한 스트링을 리턴.
구현 클래스 : CharBuffer , String , StringBuffer |
모든 버퍼류 클래스의 객체들은 toString()메서드 호출시 자신의 여러 설정들을 보여준다. 가령 예를 들어 다음과 같이 코드를 작성해서 실행을 했다고 하자.
IntBuffer buf=IntBuffer.allocate(10);
System.out.println("생성된 후:"+buf);//자동 toString() 호출....당연,,,
==>실행 결과
생성된 후 : java.nio.HeapIntBuffer[pos=0 lim=10 cap=10]
하지만 CharBuffer는 자신이 가지고 있는 char들을 보여준다. 따라서 CharBuffer의 여러 값들을 보고자 할때에는 메서드를 사용해야 한다.CharBuffer에는 위같은 사실만 알고 있으면 사용하는데는 별 무리가 없다.
1> 예제
import java.nio.*;
public class CharBufferTest {
public static void main(String[] args) {
// CharBuffer에 String 문자열로 wrap한다.
String s="String 문자열";
CharBuffer buf=CharBuffer.wrap(s);
// 버퍼의 값들을 알기 위해서는 다른 클래스와는 달리 메서드를 사용해야 한다.
System.out.println("pos:"+buf.position()+" limit:"+buf.limit()+" cap:"+buf.capacity());
buf.clear();
while(buf.hasRemaining()){
System.out.print(buf.get());//출력
}
System.out.println("\n"+"-------------------------");
// CharBuffer에 StringBuffer 문자열로 wrap한다.
StringBuffer s2 = new StringBuffer("StringBuffer 문자열");
CharBuffer buf2=CharBuffer.wrap(s2);
System.out.println("pos:"+buf2.position()+" limit:"+buf2.limit()+" cap:"+buf2.capacity());
buf2.clear();
while(buf2.hasRemaining()){
System.out.print(buf2.get());//출력
}
}
}
|
<< 실행 결과 >>
|
C\>java CharBufferTest
pos:0 limit:10 cap:10
String 문자열
-------------------------
pos:0 limit:16 cap:16
StringBuffer 문자열 |
소스를 보면 두 개의 CharBuffer를 생성해서 하나는 String 을 데이터로, StringBuffer를 데이터로 삽입한다. 이것이 가능한 이유는 앞서 말했지만 CharSequence 인터페이스를 구현하기 때문이다. 그리고 CharBuffer의 객체를 출력시 값을 알기위해서 다음과 같이 출력함을 볼 수 있다.
System.out.println("pos:"+buf.position()+" limit:"+buf.limit()+" cap:"+buf.capacity());



{kind=link}