[펌] : http://javacan.tistory.com/entry/58
서블릿 2.3에 새롭게 추가된 필터가 무엇이며, 어떻게 구현하는지에 대해서 살펴본다.
필터!!
현재 서블릿 2.3 규약은 Proposed Final Draft 2 상태에 있다. 조만간 서블릿 2.3과 JSP 1.2 최종 규약이 발표될 것으로 예상되며 우리는 당연히 새롭게 추가된 것들이 무엇인지에 관심이 쏠리게 된다. 서블릿 2.3 규약에 새롭게 추가된 것 중에 필자가 가장 눈여겨 본 것은 바로 필터(Filter) 기능의 추가이다.
그 동안 필자는 서블릿 2.2와 JSP 1.1에 기반하여 웹 어플리케이션을 구현하는 동안 몇몇 부분에서 서블릿 2.2 규약의 부족한 면을 느낄 수 있었으며, 특히 사용자 인증 처리, 요청 URL에 따른 처리, XSL/T를 이용한 XML 변환(Transformation) 등 개발자들이 직접 설계해야 하는 부분이 많았었다. 하지만, 이제 서블릿 2.3 규약에 새롭게 추가된 필터(Filter)를 사용함으로써 개발자들이 고민해야 했던 많은 부분을 덜어낼 수 있게 되었다. 이 글에서는 필터가 무엇이며 어떻게 필터를 구현하는지에 대해 살펴볼 것이다.
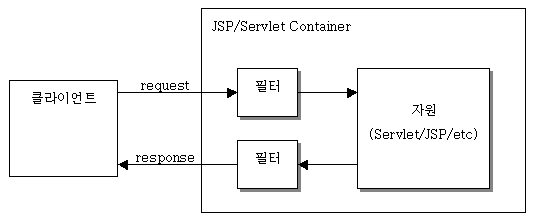
간단하게 말해서, 필터는 'HTTP 요청과 응답을 변경할 수 있는 재사용가능한 코드'이다. 필터는 객체의 형태로 존재하며 클라이언트로부터 오는 요청(request)과 최종 자원(서블릿/JSP/기타 문서) 사이에 위치하여 클라이언트의 요청 정보를 알맞게 변경할 수 있으며, 또한 필터는 최종 자원과 클라이언트로 가는 응답(response) 사이에 위치하여 최종 자원의 요청 결과를 알맞게 변경할 수 있다. 이를 그림으로 표현하면 다음과 같다.
그림1 - 필터의 기본 구조그림1에서 자원이 받게 되는 요청 정보는 클라이언트와 자원 사이에 존재하는 필터에 의해 변경된 요청 정보가 되며, 또한 클라이언트가 보게 되는 응답 정보는 클라이언트와 자원 사이에 존재하는 필터에 의해 변경된 응답 정보가 된다. 위 그림에서는 요청 정보를 변경하는 필터와 응답 정보를 변경하는 필터를 구분해서 표시했는데 실제로 이 둘은 같은 필터이다. 단지 개념적인 설명을 위해 그림1과 같이 분리해 놓은 것 뿐이다.
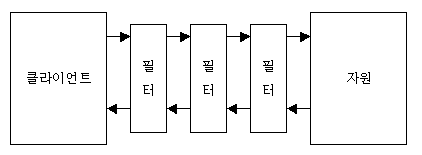
필터는 그림1에서처럼 클라이언트와 자원 사이에 1개가 존재하는 경우가 보통이지만, 여러 개의 필터가 모여 하나의
체인(chain; 또는 사슬)을 형성할 수도 있다. 그림2는 필터 체인의 구조를 보여주고 있다.
그림2 - 필터 체인그림2와 같이 여러 개의 필터가 모여서 하나의 체인을 형성할 때 첫번째 필터가 변경하는 요청 정보는 클라이언트의 요청 정보가 되지만, 체인의 두번째 필터가 변경하는 요청 정보는 첫번째 필터를 통해서 변경된 요청 정보가 된다. 즉, 요청 정보는 변경에 변경에 변경을 거듭하게 되는 것이다. 응답 정보의 경우도 요청 정보와 비슷한 과정을 거치며 차이점이 있다면 필터의 적용 순서가 요청 때와는 반대라는 것이다. (그림2를 보면 이를 알 수 있다.)
필터는 변경된 정보를 변경하는 역할 뿐만 아니라 흐름을 변경하는 역할도 할 수 있다. 즉, 필터는 클라이언트의 요청을 필터 체인의 다음 단계(결과적으로는 클라이언트가 요청한 자원)에 보내는 것이 아니라 다른 자원의 결과를 클라이언트에 전송할 수 있다. 필터의 이러한 기능은 사용자 인증이나 권한 체크와 같은 곳에서 사용할 수 있다.
필터 관련 인터페이스 및 클래스필터를 구현하는데 있어 핵심적인 역할을 인터페이스 및 클래스가 3개가 있는 데, 그것들은 바로 javax.servlet.Filter 인터페이스, javax.servlet.ServletRequestWrapper 클래스, javax.servlet.ServletResponseWrapper 클래스이다. 이 중 Filter 인터페이스는 클라이언트와 최종 자원 사이에 위치하는 필터를 나타내는 객체가 구현해야 하는 인터페이스이다. 그리고 ServletRequestWrapper 클래스와 SerlvetResponseWrapper 클래스는 필터가 요청을 변경한 결과 또는 응답을 변경할 결과를 저장할 래퍼 클래스를 나타내며, 개발자는 이 두 클래스를 알맞게 상속하여 요청/응답 정보를 변경하면 된다.
Filter 인터페이스먼저, Filter 인터페이스부터 살펴보자. Filter 인터페이스에는 다음과 같은 메소드가 선언되어 있다.
- public void init(FilterConfig filterConfig) throws ServletException
필터를 웹 콘테이너내에 생성한 후 초기화할 때 호출한다.
- public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws java.io.IOException, ServletException
체인을 따라 다음에 존재하는 필터로 이동한다. 체인의 가장 마지막에는 클라이언트가 요청한 최종 자원이 위치한다.
- public void destroy()
필터가 웹 콘테이너에서 삭제될 때 호출된다.
위 메소드에서 필터의 역할을 하는 메소드가 바로 doFilter() 메소드이다. 서블릿 콘테이너는 사용자가 특정한 자원을 요청했을 때 그 자원 사이에 필터가 존재할 경우 그 필터 객체의 doFilter() 메소드를 호출하며, 바로 이 시점부터 필터가 작용하기 시작한다. 다음은 전형적인 필터의 구현 방법을 보여주고 있다.
public class FirstFilter implements javax.servlet.Filter {
public void init(FilterConfig filterConfig) throws ServletException {
// 필터 초기화 작업
}
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
// 1. request 파리미터를 이용하여 요청의 필터 작업 수행
// 2. 체인의 다음 필터 처리
chain.doFilter(request, response); // 3. response를 이용하여 응답의 필터링 작업 수행
}
public void destroy() {
// 주로 필터가 사용한 자원을 반납
}
}
위 코드에서 Filter 인터페이스의 doFilter() 메소드는 javax.servlet.Servlet 인터페이스의 service() 메소드와 비슷한 구조를 갖는다. 즉 만약 클라이언트의 자원 요청이 필터를 거치는 경우, 클라이언트의 요청이 있을 때 마다 doFilter() 메소드가 호출되며, doFilter() 메소드는 서블릿과 마찬가지로 각각의 요청에 대해서 알맞은 작업을 처리하게 되는 것이다.
위 코드를 보면 doFilter() 메소드는 세번째 파라미터로 FilterChain 객체를 전달받는 것을 알 수 있다. 이는 클라이언트가 요청한 자원에 이르기까지 클라이언트의 요청이 거쳐가게 되는 필터 체인을 나타낸다. FilterChain을 사용함으로써 필터는 체인에 있는 다음 필터에 변경한 요청과 응답을 건내줄 수 있게 된다.
위 코드를 보면서 우리가 또 하나 알아야 하는 것은 요청을 필터링한 필터 객체가 또 다시 응답을 필터링한다는 점이다. 위 코드의 doFilter() 메소드를 보면 1, 2, 3 이라는 숫자를 사용하여 doFilter() 메소드 내에서 이루어지는 작업의 순서를 표시하였는데, 그 순서를 다시 정리해보면 다음과 같다.
- request 파리미터를 이용하여 클라이언트의 요청 필터링
1 단계에서는 RequestWrapper 클래스를 사용하여 클라이언트의 요청을 변경한다.
- chain.doFilter() 메소드 호출
2 단계에서는 요청의 필터링 결과를 다음 필터에 전달한다.
- response 파리미터를 사용하여 클라이트로 가는 응답 필터링
3 단계에서는 체인을 통해서 전달된 응답 데이터를 변경하여 그 결과를 클라이언트에 전송한다.
1단계와 3단계 사이에서 다음 필터로 이동하기 때문에 요청의 필터 순서와 응답의 필터 순서는 그림2에서 봤듯이 반대가 된다.
필터의 설정필터를 사용하기 위해서는 어떤 필터가 어떤 자원에 대해서 적용된다는 것을 서블릿/JSP 콘테이너에 알려주어야 한다. 서블릿 규약은 웹 어플리케이션과 관련된 설정은 웹 어플리케이션 디렉토리의 /WEB-INF 디렉토리에 존재하는 web.xml 파일을 통해서 하도록 하고 있으며, 필터 역시 web.xml 파일을 통해서 설정하도록 하고 있다.
web.xml 파일에서 필터를 설정하기 위해서는 다음과 같이 <filter> 태그와 <filter-mapping> 태그를 사용하면 된다.
<web-app>
<filter>
<filter-name>HighlightFilter</filter-name>
<filter-class>javacan.filter.HighlightFilter</filter-class>
<init-param>
<param-name>paramName</param-name>
<param-value>value</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>HighlightFilter</filter-name>
<url-pattern>*.txt</url-pattern>
</filter-mapping>
</web-app>
여기서 <filter> 태그는 웹 어플리케이션에서 사용될 필터를 지정하는 역할을 하며, <filter-mapping> 태그는 특정 자원에 대해 어떤 필터를 사용할지를 지정한다. 위 예제의 경우는 클라이언트가 txt 확장자를 갖는 자원을 요청할 경우 HithlightFilter가 사용되도록 지정하고 있다.
<init-param> 태그는 필터가 초기화될 때, 즉 필터의 init() 메소드가 호출될 때 전달되는 파라미터 값이다. 이는 서블릿의 초기화 파라미터와 비슷한 역할을 하며 주로 필터를 사용하기 전에 초기화해야 하는 객체나 자원을 할당할 때 필요한 정보를 제공하기 위해 사용된다.
<url-pattern> 태그는 클라이언트가 요청한 특정 URI에 대해서 필터링을 할 때 사용된다. 서블릿 2.3 규약의 11장을 보면 다음과 같이 url-pattern의 적용 기준을 명시하고 있다.
- '/'로 시작하고 '/*'로 끝나는 url-pattern은 경로 매핑을 위해서 사용된다.
- '*.'로 시작하는 url-pattern은 확장자에 대한 매핑을 할 때 사용된다.
- 나머지 다른 문자열을 정확한 매핑을 위해서 사용된다.
에를 들어, 다음과 같이 <filter-mapping> 태그를 지정하였다고 해 보자.
<filter-mapping>
<filter-name>AuthCheckFilter</filter-name>
<url-pattern>/pds/*</url-pattern>
</filter-mapping>
이 경우 클라이언트가 /pds/a.zip 을 요청하든 /pds/b.zip 을 요청하는지에 상관없이 AuthCheckFilter가 필터로 사용될 것이다.
<url-pattern> 태그를 사용하지 않고 대신 <servlet-name> 태그를 사용함으로써 특정 서블릿에 대한 요청에 대해서 필터를 적용할 수도 있다. 예를 들면 다음과 같이 이름이 FileDownload인 서블릿에 대해서 AuthCheckFilter를 필터로 사용하도록 할 수 있다.
<filter-mapping>
<filter-name>AuthCheckFilter</filter-name>
<servlet-name>FileDownload</servlet-name>
</filter-mapping>
<servlet>
<servlet-name>FileDownload</servlet-name>
...
</servlet>
래퍼 클래스필터가 필터로서의 제기능을 하기 위해서는 클라이언트의 요청을 변경하고, 또한 클라이언트로 가는 응답을 변경할 수 있어야 할 것이다. 이러한 변경을 할 수 있도록 해 주는 것이 바로 ServletRequestWrapper와 ServletResponseWrapper이다. 서블릿 요청/응답 래퍼 클래스를 이용함으로써 클라이언트의 요청 정보를 변경하여 최종 자원인 서블릿/JSP/HTML/기타 자원에 전달할 수 있고, 또한 최종 자원으로부터의 응답 결과를 변경하여 새로운 응답 정보를 클라이언트에 보낼 수 있게 된다.
서블릿 요청/응답 래퍼 클래스로서의 역할을 수행하기 위해서는 javax.servlet 패키지에 정의되어 있는 ServletRequestWrapper 클래스와 ServletResponseWrapper 클래스를 상속받으면 된다. 하지만, 대부분의 경우 HTTP 프로토콜에 대한 요청/응답을 필터링 하기 때문에 이 두 클래스를 상속받아 알맞게 구현한 HttpServletRequestWrapper 클래스와 HttpServletResponseWrapper 클래스를 상속받는 경우가 대부분일 것이다.
HttpServletRequestWrapper 클래스와 HttpServletResponseWrapper 클래스는 모두 javax.servlet.http 패키지에 정의되어 있으며, 이 두 클래스는 각각 HttpServletRequest 인터페이스와 HttpServletResponse 인터페이스에 정의되어 있는 모든 메소드를 이미 구현해 놓고 있다. 필터를 통해서 변경하고 싶은 정보가 있을 경우 그 정보를 추출하는 메소드를 알맞게 오버라이딩하여 필터의 doFilter() 메소드에 넘겨주기만 하면 된다. 예를 들어, 클라이언트가 전송한 "company" 파리머터의 값을 무조건 "JavaCan.com"으로 변경하는 요청 래퍼 클래스는 다음과 같이 HttpServletRequestWrapper 클래스를 상속받은 후에 getParameter() 메소드를 알맞게 구현하면 된다.
package javacan.filter;
import javax.servlet.http.*;
public class ParameterWrapper extends HttpServletRequestWrapper {
public ParameterWrapper(HttpServletRequest wrapper) {
super(wrapper);
}
public String getParameter(String name) {
if ( name.equals("company") ) {
return "JavaCan.com";
} else {
return super.getParameter(name);
}
}
}
오버라이딩한 getParameter() 메소드를 살펴보면 값을 구하고자 하는 파라미터의 이름이 "company"일 경우 "JavaCan.com"을 리턴하고 그렇지 않을 경우에는 상위 클래스(즉, HttpServletRequestWrapper 클래스)의 getParameter() 메소드를 호출하는 것을 알 수 있다.
이렇게 작성한 래퍼 클래스는 필터 체인을 통해서 최종 자원까지 전달되어야 그 효과가 있을 것이다. 즉, 최종 자원인 서블릿/JSP에서 request.getParameter("company")를 호출했을 때 ParameterWrapper 클래스의 getParameter() 메소드가 사용되기 위해서는 ParameterWrapper 객체가 HttpServletRequest 객체를 대체해야 하는데, 이는 Filter 인터페이의 doFilter() 내에서 ParameterWrapper 객체를 생성한 후 파라미터로 전달받은 FilterChain의 doFilter() 메소드를 호출함으로써 가능하다. 좀 복잡하게 느껴질지도 모르겠으나 이를 코드로 구현해보면 다음과 같이 간단한다.
package javacan.filter;
import javax.servlet.*;
import javax.servlet.http.*;
public class ParameterFilter implements Filter {
private FilterConfig filterConfig;
public ParameterFilter() {
}
public void init(FilterConfig filterConfig) {
this.filterConfig = filterConfig;
}
public void destroy() {
filterConfig = null;
}
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws java.io.IOException, ServletException {
// 요청 래퍼 객체 생성
HttpServletRequestWrapper requestWrapper =
new ParameterWrapper((HttpServletRequest)request);
// 체인의 다음 필터에 요청 래퍼 객체 전달
chain.doFilter(requestWrapper, response); }
}
응답 래퍼 클래스 역시 요청 래퍼 클래스와 비슷한 방법으로 구현된다.
앞에서도 언급했듯이 요청 정보의 변경 및 응답 정보 변경의 출발점은 래퍼 클래스이다. XML+XSL/T 기법이나 사용자 인증과 같은 것들을 최종 자원과 분리시켜 객체 지향적으로 구현하기 위해서 요청/응답 래퍼 클래스를 사용하는 것은 필수적이다. 2부에서 실제 예를 통해서 어떻게 필터와 요청/응답 래퍼 클래스를 효과적으로 사용할 수 있는 지 살펴보게 될 것이다.
필터 체인의 순서앞에서 필터는 체인을 형성할 수 있다고 하였다. 체인을 형성한다는 것은 어떤 특정한 순서에 따라 필터가 적용된다는 것을 의미한다. 예를 들면, 여러분은 '인증필터->파라미터 변환 필터->XSL/T 필터->자원->XSL/T 필터->파라미터 변환 필터->인증필터'와 같이 특정 순서대로 필터를 적용하길 원할 것이다. 서블릿2.3 규약은 다음과 같은 규칙에 기반하여 필터 체인 내에서 필터의 적용 순서를 결정한다.
- url-pattern 매칭은 web.xml 파일에 표기된 순서대로 필터 체인을 형성한다.
- 그런 후, servlet-name 매칭이 web.xml 파일에 표기된 순서대로 필터 체인을 형성한다.
결론이번 1 부에서는 서블릿 2.3 규약에 새롭게 추가된 필터가 무엇인지 그리고 필터를 어떻게 구현하며 또한 필터를 어떻게 서블릿이나 JSP와 같은 자원에 적용할 수 있는지에 대해서 알아보았다. 아직 구체적으로 필터의 응용방법에 대해서 설명하지 않았기 때문에 필터의 장점이 머리에 떠오르지 않을것이다. 다음 2 부에서는 구체적으로 필터의 예를 살펴봄으로써 필터의 활용함으로써 얻게 되는 장점에 대해서 살펴보도록 하자.
관련링크: