2023. 5. 31. 23:27
스마트모니터 M7 S43BM701 43인치 4K UHD IPTV 구매 후기 카테고리 없음2023. 5. 31. 23:27
..
..
..
.
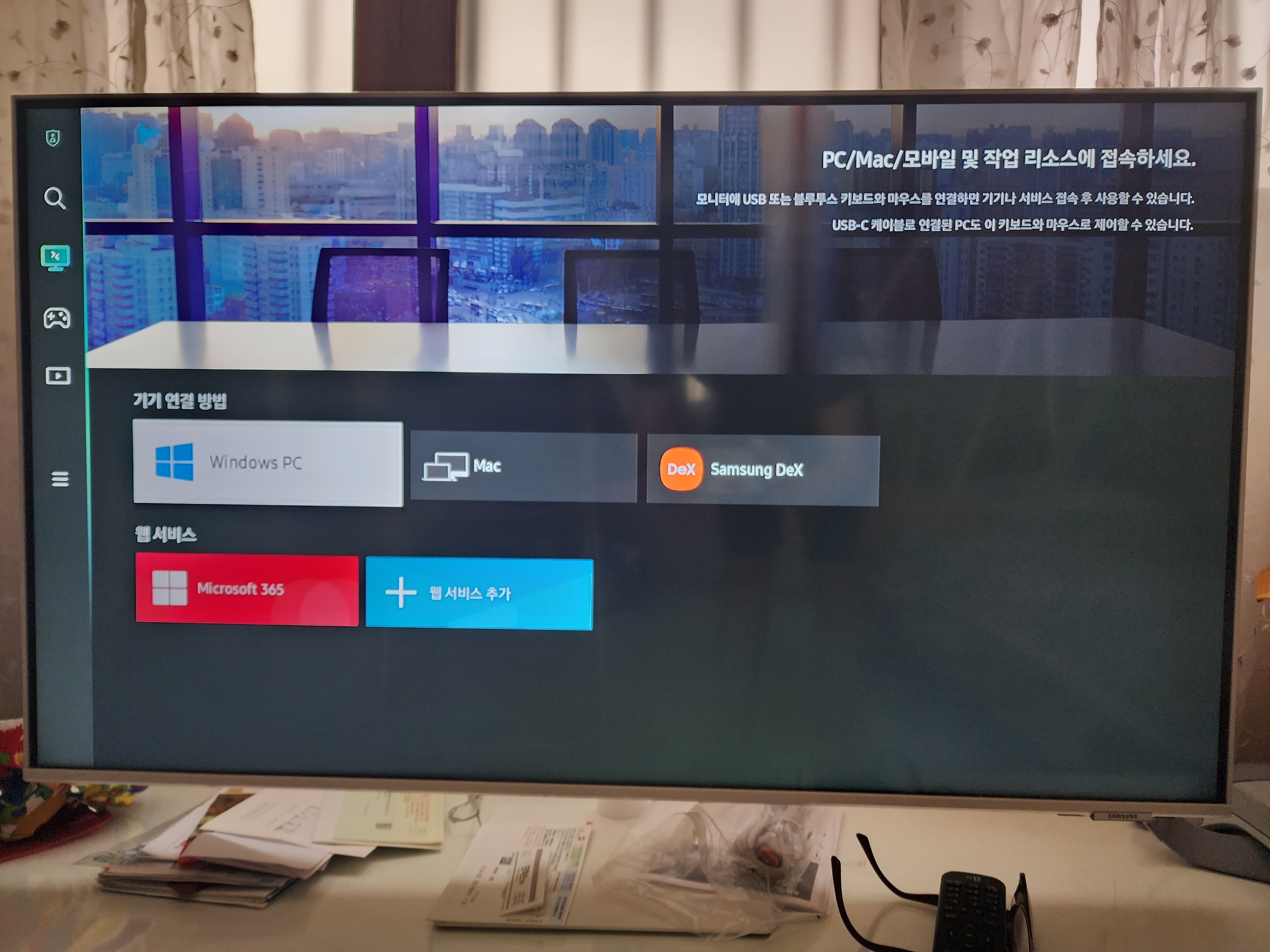





TV와 모니터 기능이 모두 필요하여 구매하였습니다. 특히 윈도우 원격 접속 기능에 대한 기대가 컸는데
업무 자체를 원격으로 하다 보니 PC나 노트북이 필요없게 되어 좀더 자유로운 환경이 되었습니다.
스탠드에 연결 후 일을 할 수 있는 환경(거실/안방/주방식탁 등)으로 이동시켜서 업무를 한다는 장점은
제품 선택을 위한 주요 요소였으며, 스마트 TV 기능을 잘 조합하면 자녀의 시청 환경에도 좋은 영향을 줄 수 있어 선택하였습니다.
#삼성모니터 #43인치모니터 #삼성TV #S43BM701#스마트모니터


